Retrieval-Augmented Generation (RAG): A Practical Guide from the Trenches
- Shantanu Sharma

- Dec 28, 2025
- 6 min read
Updated: Feb 7

Table of Content
Why RAG Is Essential for Reliable LLMs at Scale
RAG Explained: Enhancing LLM Reliability Through Contextual Retrieval
The RAG Framework: Core Components
Inside the RAG Pipeline: Retrieval, Augmentation, and Generation
Building Production-Grade RAG: Overcoming Challenges and Measuring What Matters
Real-World Applications of RAG
RAG vs. Fine-Tuning: Pick the Right Tool
Conclusion: The Future of RAG
Bibliography
I've designed, built, and deployed multiple production RAG systems across diverse use cases - enterprise search, customer support automation, internal knowledge management, contact center call driver analysis (identifying root causes and problem patterns), and automated quality assessment frameworks.
Retrieval-Augmented Generation (RAG) is a practical way to make large language models (LLMs) smarter and more reliable. It works by letting the model retrieve relevant information from external sources before generating an answer. This simple addition fixes the biggest problems with plain LLMs: outdated knowledge, hallucinations, and no access to your private data. The result is answers that are more accurate, up to date, and firmly grounded in real facts.
This article explains RAG clearly from the basics to production-ready insights.
Why RAG Is Essential for Reliable LLMs at Scale
Large language models are powerful, but they have three major flaws:
Knowledge cutoff: They only know what was in their training data. Anything newer? They're clueless.
Hallucinations: They confidently make up facts.
No private data: They can't access your company's documents or specialized information.
RAG fixes this by letting the LLM "look up" information before answering. It's like giving the model a search engine plus notes, so responses stay grounded and current.
At scale, RAG’s real value isn't just better answers—it’s consistency. It moves the needle from unpredictable guesses to reliable accuracy, turning a fragile demo into a production tool users actually trust.
RAG Explained: Enhancing LLM Reliability Through Contextual Retrieval
At its core, RAG is a hybrid system that "retrieves" relevant information from a knowledge base (like documents, databases, or web content) and "augments" the input prompt to an LLM before "generating" a response. Unlike standard LLMs that rely solely on their pre-trained knowledge (which can be outdated or incomplete), RAG pulls in fresh, context-specific data to produce better outputs.
Why do we need RAG? LLMs like GPT or Llama are trained on vast datasets but can "hallucinate" — inventing facts when they lack information. RAG mitigates this by fetching verified data, improving reliability for applications like question-answering, chatbots, and content creation.
The RAG Framework: Core Components
Limitations of Traditional LLMs
Before diving into RAG, let's understand the problems it solves. Standard LLMs generate text based on patterns learned during training. However, they often produce inaccurate or fabricated information due to hallucination. For example, an LLM might confidently state incorrect facts or outdated statistics because its knowledge cutoff is fixed.
Core Components of RAG
RAG breaks down into three main stages:
Retrieval: Search for relevant documents using the user's query.
Augmentation: Combine the retrieved information with the original query to form an enriched prompt.
Generation: Feed the augmented prompt to an LLM to produce the final response.
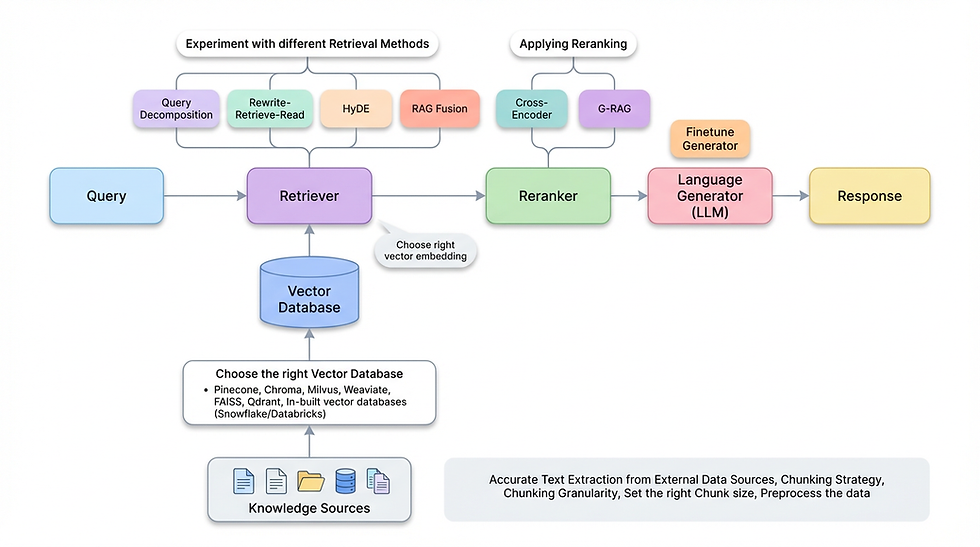
This process ensures responses are fact-based and contextually accurate. Here's a step-by-step illustration of how a RAG pipeline works, from query input to generated output.

Inside the RAG Pipeline: Retrieval, Augmentation, and Generation
The Retrieval Process
Retrieval starts with converting text into numerical representations called vector embeddings. These embeddings capture semantic meaning, allowing the system to find similar content via "semantic search" — matching based on meaning rather than exact keywords. For instance, a query like "What is climate change?" might retrieve documents about global warming, even if the exact phrase isn't present.
This above shows vector embeddings in action for semantic search, highlighting how text is mapped to multi-dimensional space for similarity matching.
Common tools for retrieval include vector databases like Pinecone, FAISS, or Weaviate, which store embeddings efficiently.
Augmentation and Generation
Once relevant chunks (e.g., paragraphs or sentences) are retrieved, they're appended to the user's query in the prompt. For example:
Original prompt: "Explain quantum computing."
Augmented: "Explain quantum computing. Relevant info: [retrieved text about qubits and superposition]."
The LLM then generates a response using this context, reducing errors.
Building Production-Grade RAG: Overcoming Challenges and Measuring What Matters
Challenges in RAG
As you scale RAG, issues arise:
Relevance: Retrieved documents might be noisy or irrelevant.
Latency: Searching large databases can be slow.
Cost: Embedding and retrieval add computational overhead.
Freshness: Knowledge bases need regular updates.
Advanced Techniques
To address these, advanced RAG incorporates:
Reranking: Use a secondary model to score and reorder retrieved documents for better precision.
Hybrid Search: Combine keyword (e.g., BM25) and semantic search for robust results.
Multi-Hop Retrieval: For complex queries, retrieve iteratively (e.g., first fetch summaries, then details).
Fine-Tuning: Train the retriever or generator on domain-specific data.
Modular RAG: Break into reusable modules for flexibility, like separate indexing and querying pipelines.
RAG Architecture Variants
RAG systems can be categorized by their complexity and decision-making logic:
Naive RAG: The foundational approach, consisting of a straightforward "retrieve-then-generate" pipeline without additional processing.
Advanced RAG: Enhances the basic flow with sophisticated pre-retrieval and post-retrieval steps, such as query expansion, document reranking, or summarization.
Adaptive RAG: An intelligent framework that dynamically evaluates query complexity to decide whether to retrieve external data, which model to use, or if the LLM can answer accurately on its own.

Measuring Success: Evaluation and Metrics
To move RAG from a demo to a production-grade system, you must move beyond "vibe checks" and use objective metrics. Evaluation is typically split into three layers:
Retrieval Performance: Measures how well the system finds the right information. Key metrics include
Precision@K: How many retrieved documents are relevant.
Recall@K: How many relevant documents were found.
Mean Reciprocal Rank (MRR): How high the first relevant result appears in the list.
Generation Quality: Evaluates the LLM's final response. While traditional NLP metrics like ROUGE and BLEU measure text similarity, they are often supplemented by human evaluation to judge nuance, tone, and coherence.
End-to-End Reliability: Focuses on the relationship between the retrieved data and the answer. This includes
Faithfulness: Ensuring the answer is strictly grounded in the retrieved context to prevent hallucinations.
Answer Relevancy: Ensuring the response actually addresses the user's query.
Frameworks like RAGAS and DeepEval are now industry standards for automating these measurements, allowing teams to iterate on their RAG pipelines with data-driven confidence.
Real-World Applications of RAG
RAG already powers many production AI systems, including:
Chatbots: Enterprise assistants that query internal documents, wikis, and tickets to provide accurate, context-aware answers.
Search Experiences: Search interfaces enhanced with generative summaries grounded in retrieved documents.
Content Creation: Writing tools that pull relevant facts and references for articles, reports, and documentation.
Healthcare & Legal: Assistants that retrieve from vetted, specialized knowledge bases to support more informed, compliant recommendations.
RAG vs. Fine-Tuning: Pick the Right Tool
People often ask which is better — RAG vs. Fine-Tuning. This summary table will help you quickly see which option fits your use case.
Aspect | RAG | Fine-Tuning |
Updates | Easy—just add/update docs | Retrain the whole model (expensive, slow) |
Private/current data | Perfect | Possible, but static after training |
Hallucinations | Reduced (grounded in retrieval) | Reduced, but no external check |
Cost | Lower ongoing | High compute for training |
Style/task adaptation | Limited | Great (e.g., tone, format) |
Best for | Factual Q&A over your data | Specialized behavior or small datasets |
Conclusion: The Future of RAG
RAG bridges the gap between static LLMs and dynamic knowledge, making AI more trustworthy and versatile. For beginners, start with simple setups; intermediates can experiment with libraries; advanced users should focus on optimization and evaluation. As AI evolves, expect RAG to integrate with multimodal data (images, video) and real-time web retrieval.
By mastering RAG, you can build AI systems that are not just smart, but reliably informed. If you're implementing this, begin with open-source tools and iterate based on your domain's needs.
Bibliography
Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems: https://arxiv.org/abs/2005.11401
Retrieval-augmented generation for large language models: https://arxiv.org/abs/2312.10997
A comprehensive survey of retrieval-augmented generation (RAG): Evolution, current landscape and future directions: https://arxiv.org/abs/2410.12837
Retrieval-augmented generation for AI-generated content: https://arxiv.org/abs/2402.19473
Ragas: Automated evaluation of retrieval augmented generation: https://arxiv.org/abs/2309.15217
Build a retrieval augmented generation (RAG) app: https://python.langchain.com/docs/tutorials/rag/
Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools: https://dho.stanford.edu/wp-content/uploads/Legal_RAG_Hallucinations.pdf



Comments